
Retrieval Augmented Generation
Quick tutorial on creating RAG based bots
Introduction to RAG
In the ever-evolving world of conversational AI, RAG (Retrieval-Augmented Generation) stands out as an innovative approach that combines the strengths of information retrieval with generative language models. RAG models offer the best of both worlds by enhancing the accuracy and relevance of responses using a retrieval mechanism that feeds information to a generative model like GPT.
Instead of solely relying on the generative model’s pre-trained knowledge, RAG bots dynamically retrieve contextually relevant information from a database or knowledge base to inform their responses. This leads to more accurate, up-to-date, and context-aware conversations.
How RAG Works
A RAG system works in two main steps:
- Retrieval: When a user sends a query, the system retrieves relevant information from a knowledge base. This is powered by semantic search, which uses vector embeddings to understand the intent and context of the query.
- Generation: The retrieved information is passed as context to the large language model (LLM), such as OpenAI’s GPT, which generates a response based on this information.
This method significantly improves the quality of answers, especially for queries requiring specific knowledge outside the model's pre-trained data.
SentiOne Automate's RAG Capabilities
Documents - Vector-Based Semantic Search
Semantic search is delivered in SentiOne Automate in a feature called Documents which is part of the Knowledge Base. You can easily index new pieces of information directly through the UI. This feature allows bots to retrieve highly relevant information based on the meaning and context of user utterances, not just keyword matching.
The semantic search works by:
- Generating vector embeddings of data entries (e.g., FAQs, documents, or support articles).
- Comparing user queries to these embeddings to identify the most relevant content.
- Providing the most contextually accurate information for the conversation.
This retrieval mechanism ensures that the most suitable information is identified and delivered to the LLM for response generation.
The "LLM Say" Block
To facilitate the creation of RAG bots, SentiOne Automate includes a block: “LLM Say”. This block allows direct integration with the OpenAI API, enabling bots to leverage state-of-the-art LLMs such as GPT-4o-mini or GPT-4. The “LLM Say” block works as follows:
- Retrieve Relevant Data: Before calling the LLM, use SentiOne Automate’s semantic search feature to retrieve the most relevant pieces of information based on the user query.
- Generate a Context-Aware Response: Pass the retrieved data into the “LLM Say” block, which sends the data as context to the OpenAI API or other leading LLMs
- Receive and Send the Response: The LLM model generates a contextually informed response, which the bot then delivers to the user as stream.
Example Workflow in SentiOne Automate
Here’s an example of how to create a RAG-powered bot workflow in SentiOne Automate:
- User Query: The user asks, “How do I reset my password?”
- Execute knowledge.semanticSearch function
- Retrieve the most relevant FAQs or support articles related to password resets using semantic search based on vector embeddings.
- “LLM Say” Block:
- Input: The retrieved context (e.g., “To reset your password, go to Settings > Security > Reset Password.”)
- Send this context to the OpenAI API with a prompt like: “Using the following information, answer the user's query: [retrieved content].”
- Response:
- The LLM generates a tailored, informative response: “To reset your password, go to Settings > Security > Reset Password. If you need further assistance, feel free to ask!”
- Bot Sends Response:
- The bot sends the generated answer back to the user.
- The response can be streamed directly as tokens appear or buffered for better quality of speech synthesis (TTS) Both webchat and voice channel connectors support streaming.\
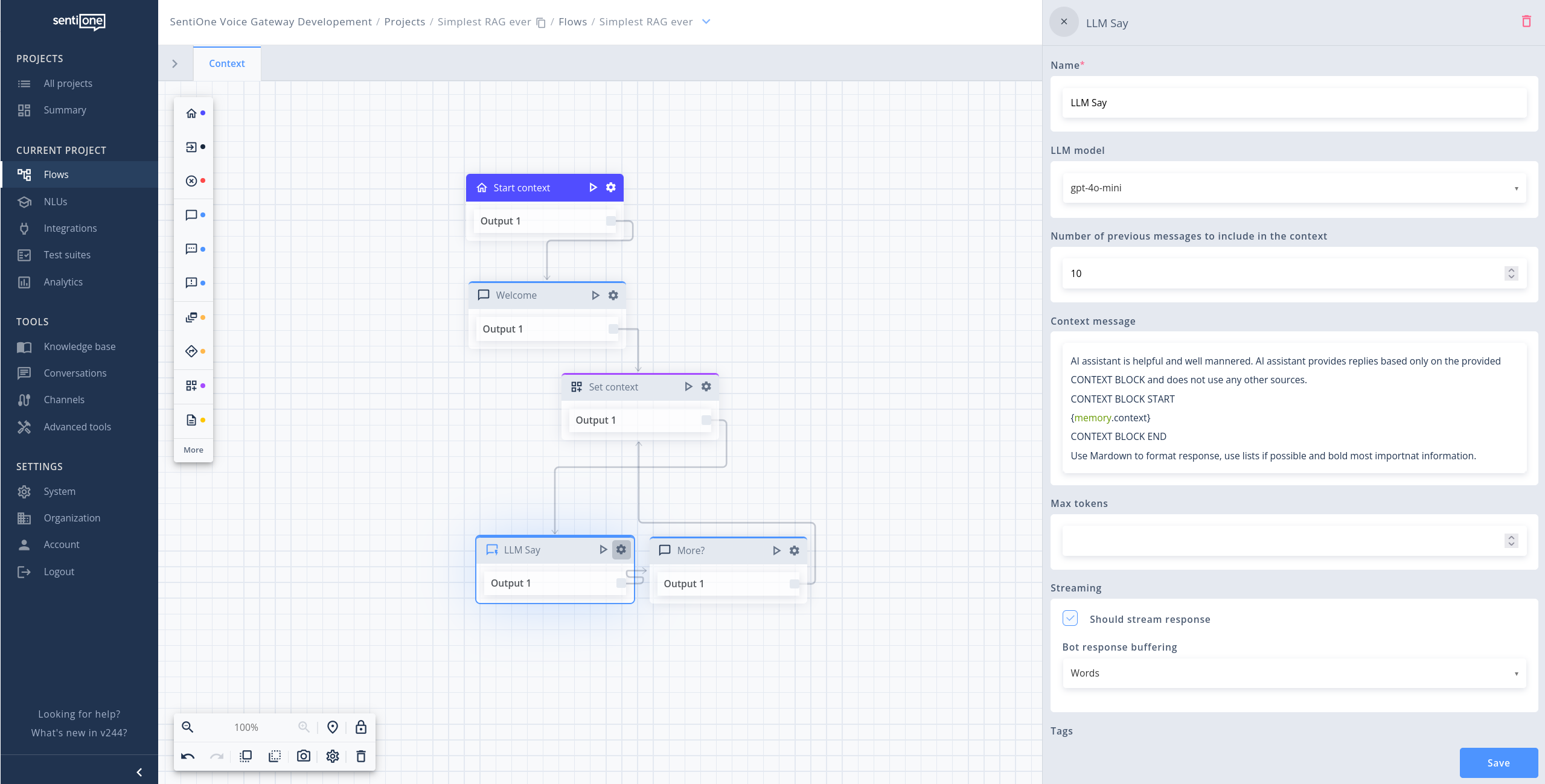
The most basic RAG flow
Benefits of RAG Bots in SentiOne Automate
1. Increased Accuracy
By retrieving contextually relevant data before generating a response, RAG bots provide more accurate and specific answers, reducing the risk of hallucinations or irrelevant replies.
2. Dynamic and Up-to-Date Responses
Unlike static pre-trained models, RAG bots can pull the latest information from knowledge sources, ensuring users receive up-to-date responses.
3. Flexibility and Customization
The combination of semantic search and the “LLM Say” block allows developers to fine-tune the data retrieval process and prompt structure for more tailored and brand-specific interactions.
4. Scalability
Whether handling a small FAQ dataset or an extensive knowledge base, SentiOne Automate’s RAG implementation scales effectively, ensuring high-quality responses even with large datasets.
Updated 9 months ago