
LLM Say
The LLM Say Block's main goal is to accept user input and stream the message.
Here are main parameters that help us to optimize the answer:
- LLM Model - we can choose which model will be the most suitable for our task
- Context message (RAG) - here we use a template that has proven to be the most optimal:
{memory.query} {memory.character}. START CONTEXT BLOCK {memory.context} END OF CONTEXT BLOCK {memory.instructions}. Answer in maximum {memory.output_tokens} tokens. - Number of previous messages to include in the context
- Max tokens - NOT output limit, this is a number of tokens after which the message will be cut short
- Streaming - This parameter defines how we want to display the message from the bot.
- None - chunk by chunk (more or less letter by letter)
- Words - word by word
- Full sentences - sentence by sentence
Changing this parameter is useful when configuring voice bots (they can't properly read with None and Words)
Tool calling
The LLM Say block can also be used in the form of Tool Calling. Tool Calling is a feature that enhances conversational AI by enabling it to interact with external systems and data sources in real time, making bots more powerful and intelligent than ever.
Its key advantage is the ability to go beyond static, pre-trained knowledge and access up-to-date information. This allows bots to deliver real-time answers and perform tasks that rely on live data. By connecting to internal or third-party APIs, your AI can integrate seamlessly with existing business workflows.
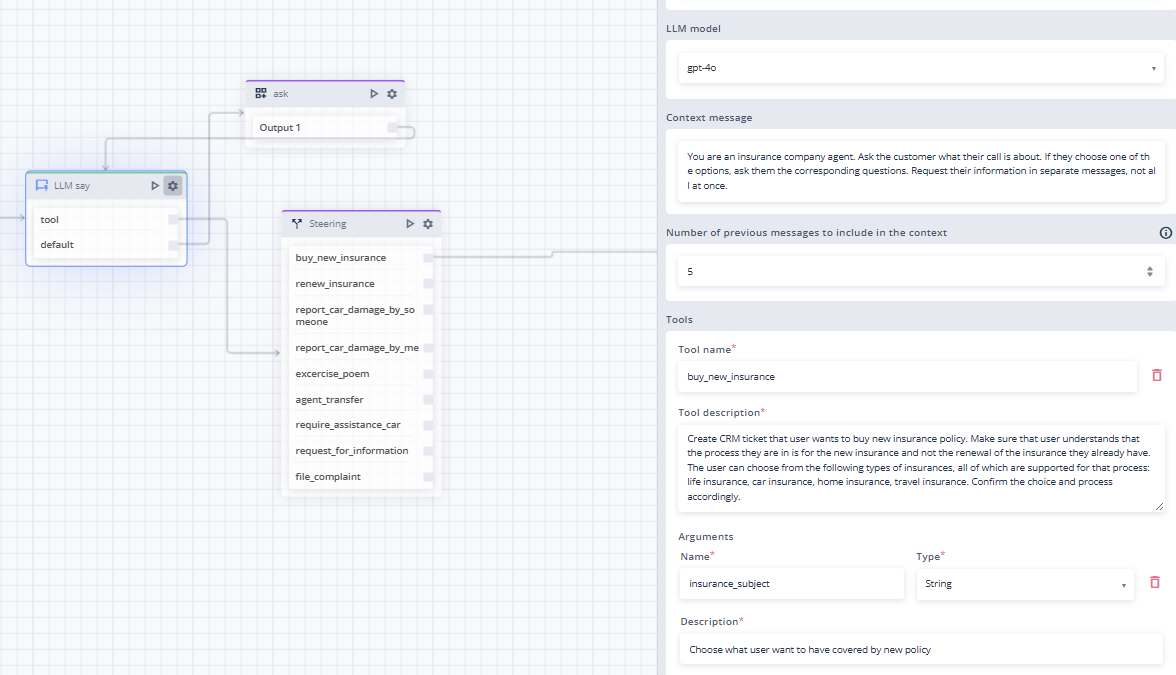
This feature can function like an AI router, but with the added capability of defining exactly what information is required from the customer in a given context. It proactively gathers the necessary details step by step, and only once all relevant data is collected does it direct the conversation to the appropriate process or workflow.
It operates on a question–answer loop, exiting only once sufficient information has been obtained to proceed.
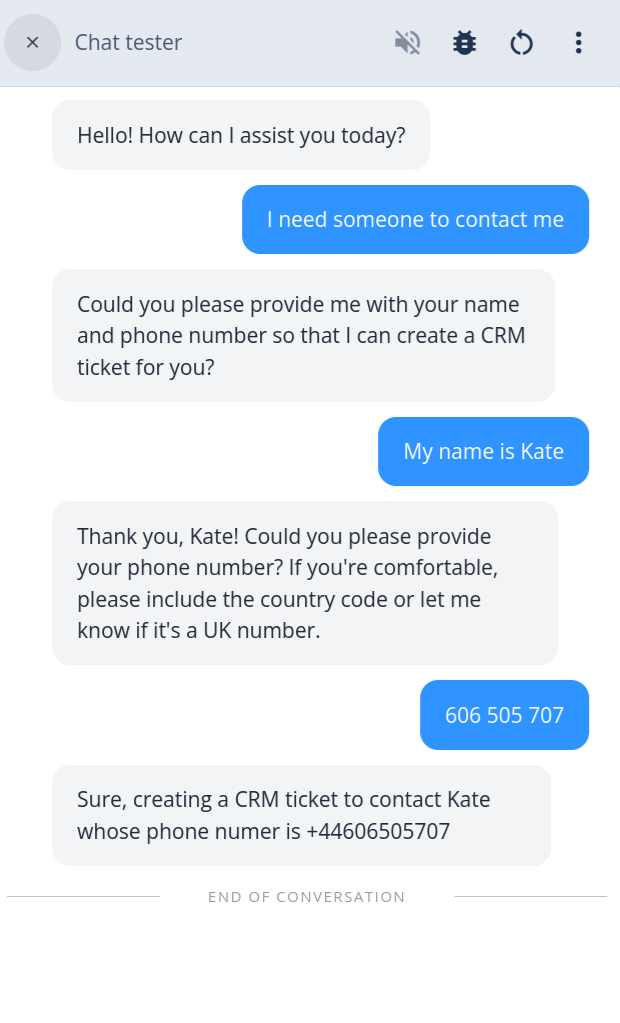
Returning Tool Call Results
After an LLM Say block executes and determines that one or more tool calls are necessary, by default it populates the memory.toolCalls path (memory path can be configured). Your workflow might then execute these tools (e.g., by calling external APIs) and return the results back to the LLM for final processing.
This is achieved by providing the results in a specific format within the memory. The LLM will then use this information to formulate a response to the user.
The toolResults Memory Path
toolResults Memory PathTo feed the results back to the model, you must place them in the toolResults memory path. The LLM Say block is configured by default to look for results at this location.
The results must be provided within the same conversational turn that the toolCalls were generated.
Required Data Structure
The tool results must be formatted as a array of objects. Each object in the array corresponds to a tool call that was executed and must contain two properties:
id: The unique identifier of the tool call. This must exactly match theidprovided in the originalmemory.toolCallsobject. This allows the LLM to correlate each result with its corresponding request.result: The data returned from your tool or API call. This can be a string, a number, etc.
Example Walkthrough
Let's walk through a complete example.
1. LLM Triggers Tool Calls
A user asks for the weather and the latest news. The first LLM Say block processes this request and, using the tools you have defined, generates the following toolCalls array in memory:
memory.toolCallsoutput:
[
{
"id": "ABC123",
"name": "get_weather",
"arguments": {
"location": "London",
"unit": "celsius"
}
},
{
"id": "DEF456",
"name": "get_news",
"arguments": {
"topic": "technology"
}
}
]
2. Your Workflow Executes the Tools
Your workflow now needs to act on this output. This typically involves:
- Iterating through the memory.toolCalls array.
- Using Integration block to call the actual APIs for
get_weatherandget_news. - Storing the result of each API call. For example, the weather API returns
{ "temp": 15, "condition": "sunny" }and the news API returns{ "headline": "New AI model released" }.
3. Construct and Provide the Results
After executing the tools, you must construct the toolResults array in the required format. You can do this using a Custom block. Notice how each id matches the original id from the toolCalls.
memory.toolResults:
[
{
"id": "ABC123",
"result": {
"temp": 15,
"condition": "sunny"
}
},
{
"id": "DEF456",
"result": {
"headline": "New AI model released"
}
}
]4. LLM Formulates the Final Response
With the toolResults now in memory, the conversation returns to the initial LLM Say block. This block automatically ingests the results, understands their context in relation to the initial user query, and generates a final, user-friendly response.
The final output to the user might be:
"The current weather in London is 15°C and sunny. The top technology headline is: 'New AI model released'."
Updated 9 months ago